Kubernetes网络模型
一切都是为了通!
——阅读《深入剖析Kubernetes》第7章有感
为了聚合算力,为了屏蔽基础设施的差异,要让Pod相互连通是重大且现实的问题。
k8s为了解决Pod间的网络连通设置了CNI接口来供各方实现,这样就可以解耦与某种特定网络方案之间的绑定,类似的设计思想在k8s上还体现在CRI和CSI接口的设置上。现在已经有许多实现了CNI接口的成熟的网络方案,比较知名的有flannel、Calico和Cilium。
单机容器互联
Docker容器网络有四种模式,host、none、bridge和container,在启动容器的时候可以指定以哪种方式设置网络,不指定的话默认是桥接。
在默认桥接模式下,每个容器都在一个Network Namespace中并且有一张veth网卡插在docker0虚拟交换机上,容器之间的相互通信是通过交换机广播ARP在二层实现的,容器和宿主机之间的通信是通过设置容器的路由表找到插在宿主机上的与docker0网桥同名的docker0网卡实现的。网络流量可以通过tcpdump指定网卡抓包查看,网桥设备也可以通过brctl查看,并且可以查看插在虚拟网桥上的veth pair设备。

这里有个小技巧,如果我们想查看k8s集群内DNS请求的情况,但是DNS容器往往不具备bash,所以无法通过docker exec的方式进入容器内抓包,这时可以进入该容器的Network Namespace,再抓包。
// 1、找到CONTAINER_ID,并打印它的NS_ID
docker inspect --format "{{.State.Pid}}" $CONTAINER_ID
// 2、进入该容器的Network Namespace
nsenter -n -t $NS_ID
// 3、抓DNS包
tcpdump -i eth0 udp dst port 53
容器跨主互联
flannel
k8s经典的网络解决方案是flannel。
Flannel may be paired with several different backends. Once set, the backend should not be changed at runtime.
VXLAN is the recommended choice. host-gw is recommended for more experienced users who want the performance improvement and whose infrastructure support it (typically it can’t be used in cloud environments). UDP is suggested for debugging only or for very old kernels that don’t support VXLAN.
VXLAN
Use in-kernel VXLAN to encapsulate the packets.
host-gw
Use host-gw to create IP routes to subnets via remote machine IPs. Requires direct layer2 connectivity between hosts running flannel.
host-gw provides good performance, with few dependencies, and easy set up.
UDP
Use UDP only for debugging if your network and kernel prevent you from using VXLAN or host-gw.
flannel有三种后端实现,UDP、VXLAN和host-gw,其中UDP模式已经废弃,只在调试或者网络和内核不支持使用host-gw和VXLAN模式时可以选择使用。但是UDP模式也是最好理解的模式。
UDP mode
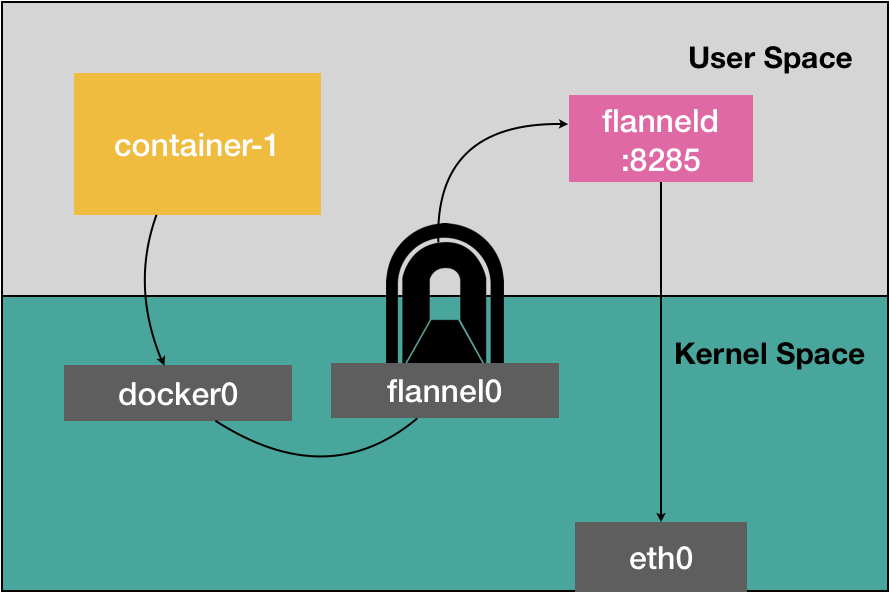
UDP模式的核心是在每个节点上创建了flannel0网络设备和flanneld守护进程,依靠封包和解包这种隧道模式在节点之间建立起overlay网络。
当本机的pod想发送请求到其他节点上的pod时,由于目的地址不在docker0网段,所以会被docker0网桥发送至宿主机的docker0网卡上,此时查找路由表,由于路由表规则已经被flanneld提前写入,所以会转发到一个叫flannel0的网络设备上,该设备是一个TUN设备,这种设备会将存在于内核态中的网络包转发给创建该网络设备的用户态的进程,在此就是flanneld进程,flanneld进程就会发起一个UDP连接将数据包转发至目标主机,这就是flannel UDP模式的大致流程。其中subnet和宿主机的关系是保存在etcd中。
从网络协议栈的横截面来看的话,从docker0由经路由表转发到flannel0是内核态的操作,flannel0转发给flanneld会从内核态到用户态,而flanneld对数据进行封包以后会再次流过协议栈到eth0网卡转发给其他主机,这其中需要经历三次内核态和用户态之间的复制,严重影响性能。
VXLAN mode
VXLAN模式和UDP模式十分类似,都是通过封包和解包的隧道模式构建overlay网络打通节点。
VXLAN模式可以利用Linux内核的VXLAN模块在内核中直接封装和解封装。这就免去了像UDP模式下内核态的flannel0流向用户态的flanneld,然后在flanneld中封包,再流向eth0这个过程。这样就提高了效率,所以VXLAN成为了主流的跨主通信方案。其中VTEP(VXLAN tunnel end point,虚拟隧道端点)就类似flannel0的作用。
VXLAN通信的过程相当复杂,具体见《深入剖析Kubernetes》P264-267。

host-gw mode
host-gw模式是一种三层网络方案,host-gw模式的工作原理非常简单,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。也就是说,这台“主机”(Host)会充当这条容器通信路径里的“网关”(Gateway)。这也正是“host-gw”的含义。当然,Flannel 子网和主机的信息,都是保存在 Etcd 当中的。flanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。
在 Kubernetes v1.7 之后,类似 Flannel、Calico 的 CNI 网络插件都是可以直接连接 Kubernetes 的 APIServer 来访问 Etcd 的,无需额外部署 Etcd 给它们使用。
而在这种模式下,容器通信的过程就免除了额外的封包和解包带来的性能损耗。根据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右。host-gw 模式能够正常工作的核心,就在于 IP 包在封装成帧发送出去的时候,会使用路由表里的“下一跳”来设置目的 MAC 地址。这样,它就会经过二层网络到达目的宿主机。所以说,Flannel host-gw 模式必须要求集群宿主机之间是二层连通的。这样也印证了官方对host-gw的"Requires direct layer2 connectivity between hosts running flannel.“说法。
Calico
Calico是三层转发网络解决方案的典型代表。
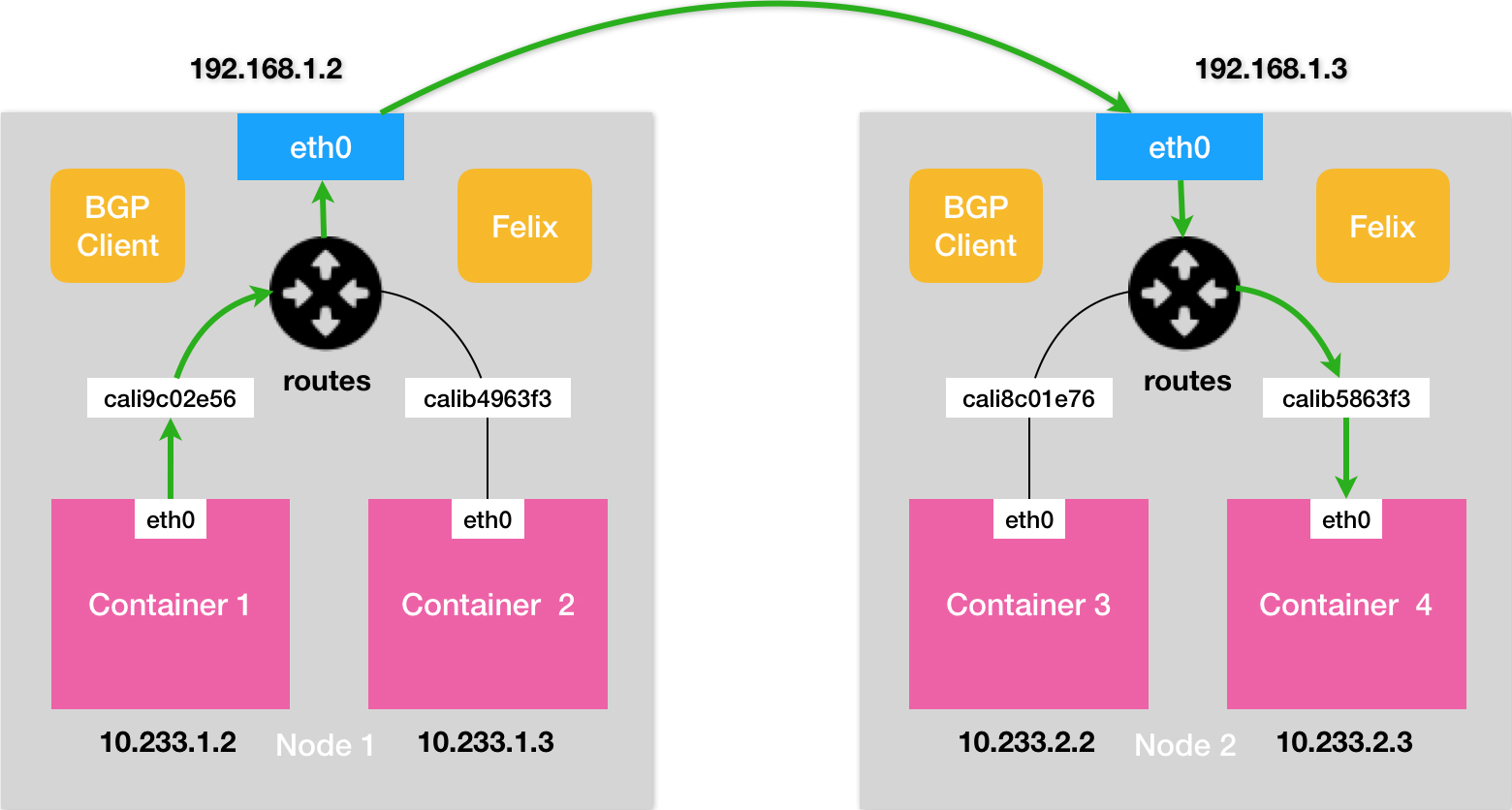
实际上,Calico 项目提供的网络解决方案,与 Flannel 的 host-gw 模式,几乎是完全一样的。也就是说,Calico 也会在每台宿主机上,添加一个去往下一个node的路由规则。
而正如前所述,这个三层网络方案得以正常工作的核心,是为每个容器的 IP 地址,找到它所对应的、“下一跳”的网关。不过,不同于 Flannel 通过 Etcd 和宿主机上的 flanneld 来维护路由信息的做法,Calico 项目使用了BGP路由客户端来自动地在整个集群中分发路由信息。BGP的工作原理可以简单理解为:在每个边界网关上都会运行着一个BGP客户端,它们会将各自的路由表信息,通过 TCP 传输给其他的边界网关。而其他边界网关上的BGP客户端,则会对收到的这些数据进行分析,然后将需要的信息添加到自己的路由表里。所谓 BGP,就是在大规模网络中实现节点路由信息共享的一种协议。
Calico项目的架构由三个部分组成:
- Calico 的 CNI 插件。
- Felix。它是一个 DaemonSet,负责在宿主机上插入路由规则(即:写入 Linux 内核的 FIB 转发信息库),以及维护 Calico 所需的网络设备等工作。
- BIRD。它就是 BGP 的客户端,专门负责在集群里分发路由规则信息。
除了对路由信息的维护方式之外,Calico 项目与 Flannel 的 host-gw 模式的另一个不同之处,就是它不会在宿主机上创建任何网桥设备。
需要注意的是,Calico 维护的网络在默认配置下,是一个被称为“Node-to-Node Mesh”的模式。这时候,每台宿主机上的 BGP Client 都需要跟其他所有节点的 BGP Client 进行通信以便交换路由信息。但是,随着节点数量 N 的增加,这些连接的数量就会以 N²的规模快速增长,从而给集群本身的网络带来巨大的压力。
所以,Node-to-Node Mesh 模式一般推荐用在少于 100 个节点的集群里。而在更大规模的集群中,则需要用到的是一个叫作 Route Reflector 的模式。
在这种模式下,Calico 会指定一个或者几个专门的节点,来负责跟所有节点建立 BGP 连接从而学习到全局的路由规则。而其他节点,只需要跟这几个专门的节点交换路由信息,就可以获得整个集群的路由规则信息了。这些专门的节点,就是所谓的 Route Reflector 节点,它们实际上扮演了“中间代理”的角色,从而把 BGP 连接的规模控制在 N 的数量级上。
此外,Flannel host-gw 模式最主要的限制,就是要求集群宿主机之间是二层连通的。而这个限制对于 Calico 来说,也同样存在。在这种情况下就需要为Calico开启IPIP模式。IPIP模式的含义就是IP in IP,就如同flannel的MAC in UDP一样是通过封包和解包的隧道模式进行传输。在实际测试中,Calico IPIP 模式与 Flannel VXLAN 模式的性能大致相当。所以,在实际使用时,如非硬性需求,建议将所有宿主机节点放在一个子网里,避免使用 IPIP。
但是如果 Calico 项目能够让宿主机之间的路由设备(也就是网关),也通过 BGP 协议“学习”到 Calico 网络里的路由规则,那么从容器发出的 IP 包,不就可以通过这些设备路由到目的宿主机了么?但是在 Kubernetes 被广泛使用的公有云场景里,却完全不可行。这里的原因在于:公有云环境下,宿主机之间的网关,肯定不会允许用户进行干预和设置。当然,在大多数公有云环境下,宿主机(公有云提供的虚拟机)本身往往就是二层连通的,所以这个需求也不强烈。不过,在私有部署的环境下,宿主机属于不同子网(VLAN)反而是更加常见的部署状态。这时候,想办法将宿主机网关也加入到 BGP Mesh 里从而避免使用 IPIP,就成了一个非常迫切的需求。而在 Calico 项目中,已经提供了两种将宿主机网关设置成 BGP Peer 的解决方案。
- 第一种方案需要为BGP配置Dynamic Neighbors,这样就可以给路由器配置一个网段,然后路由器就会自动跟该网段里的主机建立起 BGP Peer 关系。
- 第二种方案是使用一个或多个独立组件负责搜集整个集群里的所有路由信息,然后通过 BGP 协议同步给网关。前面提到,在大规模集群中,Calico 本身就推荐使用 Route Reflector 节点的方式进行组网。所以,这里负责跟宿主机网关进行沟通的独立组件,直接由 Route Reflector 兼任即可。更重要的是,这种情况下网关的 BGP Peer 个数是有限并且固定的。所以就可以直接把这些独立组件配置成路由器的 BGP Peer,而无需 Dynamic Neighbors 的支持。
网络隔离
在 Kubernetes 里,网络隔离能力的定义,是依靠一种专门的 API 对象来描述的,即:NetworkPolicy。
一个完整的示例如下所示:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
这里需要明确,Kubernetes 里的 Pod 默认都是“允许所有”(Accept All)的,即:Pod 可以接收来自任何发送方的请求;或者,向任何接收方发送请求。而如果你要对这个情况作出限制,就必须通过 NetworkPolicy 对象来指定。而一旦 Pod 被 NetworkPolicy 选中,那么这个 Pod 就会进入“拒绝所有”(Deny All)的状态,即:这个 Pod 既不允许被外界访问,也不允许对外界发起访问。而 NetworkPolicy 定义的规则,其实就是“白名单”。例如,在上面这个例子里,在 policyTypes 字段,定义了这个 NetworkPolicy 的类型是 ingress 和 egress,即:它既会影响流入(ingress)请求,也会影响流出(egress)请求。然后,在 ingress 字段里,定义了 from 和 ports,即:允许流入的“白名单”和端口。其中,这个允许流入的“白名单”里,指定了三种并列的情况,分别是:ipBlock、namespaceSelector 和 podSelector。而在 egress 字段里,则定义了 to 和 ports,即:允许流出的“白名单”和端口。这里允许流出的“白名单”的定义方法与 ingress 类似。只不过,这一次 ipblock 字段指定的,是目的地址的网段。
综上所述,这个 NetworkPolicy 对象,指定的隔离规则如下所示:
- 该隔离规则只对 default Namespace 下的,携带了 role=db 标签的 Pod 有效。限制的请求类型包括 ingress(流入)和 egress(流出)。
- Kubernetes 会拒绝任何访问被隔离 Pod 的请求,除非这个请求来自于以下“白名单”里的对象,并且访问的是被隔离 Pod 的 6379 端口。这些“白名单”对象包括:a. default Namespace 里的,携带了 role=fronted 标签的 Pod;b. 携带了 project=myproject 标签的 Namespace 里的任何 Pod;c. 任何源地址属于 172.17.0.0/16 网段,且不属于 172.17.1.0/24 网段的请求。
- Kubernetes 会拒绝被隔离 Pod 对外发起任何请求,除非请求的目的地址属于 10.0.0.0/24 网段,并且访问的是该网段地址的 5978 端口。
而这种策略的本质也是通过iptables来控制的。
Service和DNS
Kubernetes 从 1.11 版本开始,使用 CoreDNS 替代 KubeDNS 成为了内置的 DNS 服务。
我们创建一个busybox Pod,然后执行
kubectl exec busybox cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
options ndots:5
可见搜索域是default.svc.cluster.local、svc.cluster.local和cluster.local
DNS满足了服务发现的需求。
之前我在Service简记中描述过ClusterIP和NodePort类型Service的网络原理。Service还有headless、LoadBalancer和ExternalName类型。
- LoadBalancer Service类型需要Cloud Provider的支持
- Headless Service类型返回该Service选择到的Pod的地址
- ExternalName Service可以给一个外部服务起一个内部别名
Ingress
Ingress对象提供代理七层负载均衡,可以通过设置域名和path的规则访问到内部的Service。
我们可以通过提交Ingress对象设置反向代理规则,但是真正实现反向代理功能的是Ingress-Controller。常见的Ingress-Controller有Nginx、HAproxy和traefik。k3s内置了traefik,traefik的优势就在与热加载。
以常用的Nginx实现为例,当我们提交Ingress,其实就是设置了nginx.conf,就实现了反向代理的功能。Ingress还可以方便的配置TLS。
总结
k8s的网络非常复杂,这里只是在我阅读《深入剖析Kubernetes》第七章之后的笔记和个人思考,仅仅是整个k8s网络模型中的冰山一角。例如:VXLAN技术其实是在数据中心网络中为了使虚拟机东西迁移的,CNI的调用流程,和最近流行的以eBPF技术为底座,性能十分之高的Cilium插件等等等等都没有涉及。如此复杂的网络产生的原因就是为了屏蔽底层基础设施,让node和node之间没有隔离,Pod可以自由的通过IP地址进行访问,就像在一个单一的巨大的资源大海里一样。
理解k8s网络模型是深入了解k8s的必由之路,只有深刻理解了k8s中的网络才能更好的理解k8s的设计。
